Automatic Features
Exploring automation of Feature Engineering using Neural Netwroks
Introduction:
Instead of doing Feature Engineering with hand by mean-encoding, breaking strings, trends, averages, combination of features etc. It would be nice if we could automate the feature engineering process.
Main idea being that activations in hidden layers of a deep Neural Network, are combinations of input features, generally representing lower level details or patterns to higher level details of the input data. Using these details as input features in other type of models and investigate the effects of using hidden layer activations as input features(being automatically engineered by training a Neural Network).
Instead of X as input investigating the effects of using A1, A2, … as inputs for model’s training.
- To start Pima Indians Diabetes Database from Kaggle is used:
Columns = Pregnancies, Glucose, BloodPressure, SkinThickness, Insulin, BMI, DiabetesPedigreeFunction, Age
shape = (768, 8)
- Fixed seed for reproducible results (still will vary a little):
seed = 43
import os
import random as rn
import numpy as np
import tensorflow as tf
os.environ['PYTHONHASHSEED']=str(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
rn.seed(seed)
-
Scale the data for 0 mean and unit std, using sklearn’s StandardScaler()
-
Neural Network build using Keras library, model.summary():
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 8) 0
_________________________________________________________________
dense_1 (Dense) (None, 32) 288
_________________________________________________________________
dense_2 (Dense) (None, 32) 1056
_________________________________________________________________
dense_3 (Dense) (None, 4) 132
_________________________________________________________________
dense_4 (Dense) (None, 1) 5
=================================================================
Total params: 1,481
Trainable params: 1,481
Non-trainable params: 0
_________________________________________________________________
- Adam Optimizer:
adam_opt = Adam(learning_rate=0.001,beta_1=0.9, beta_2=0.999, amsgrad=False)
- Loss and Metric:
model.compile(loss='mean_squared_error', optimizer=adam_opt, metrics=['accuracy'])
- .fit() Hypreparameters:
fit = model.fit(X_scl, Y, epochs=500, validation_split=0.3)
- XGBoost model to measure the features importance:
model = XGBClassifier(max_depth=7,
random_state=seed,
min_child_weight=15,
learning_rate=0.001,
n_estimators=400)
- Feature Importamce in XGBoost model:
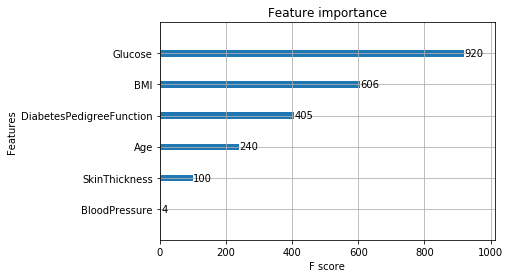
- Getting Weights and bias for hidden layer and then Calculating activation for hidden layers, using calcActivation(model, X, act) function:
# calculate activation for hidden layers
# a = g(z) = g(wx + b)
# (nl,m) (nl,n)(n,m) (nl,1)
- a1 mostly 0.0000s, sparse dataframe with relu activation:
- more hidden units than required?
- check % of zeroes in features
- L1 regularization?
- a1.sum():
- only 6 non-zero features
f1-0 129.157055
f1-1 0.000000
f1-2 0.000000
f1-3 0.000000
f1-4 0.000000
f1-5 0.000000
f1-6 0.000000
f1-7 0.000000
f1-8 0.000000
f1-9 0.000000
f1-10 192.624494
f1-11 0.000000
f1-12 0.000000
f1-13 3.890168
f1-14 0.000000
f1-15 119.354960
f1-16 0.000000
f1-17 144.222696
f1-18 0.000000
f1-19 0.000000
f1-20 0.000000
f1-21 0.000000
f1-22 0.000000
f1-23 0.000000
f1-24 0.000000
f1-25 0.000000
f1-26 0.000000
f1-27 120.874367
f1-28 0.000000
f1-29 0.000000
f1-30 0.000000
f1-31 0.000000
dtype: float64
- RELU activation function induuce sparsity
From: Xavier Glorot, Antoine Bordes and Yoshua Bengio
- 11 non-zero features using LeakyRelu with alpha as 0.01
- 32 using tanh
Output:
- Run XGBmodel:
- with X as input
- using RELU:
- with a1 as input
- with a2 as input
- using TanH:
- with a1 as input
- with a2 as input
XGB Train accuracy: 76.54%
XGB Test accuracy: 80.09%
relu:
NN train loss: 0.1564963618414806
NN val loss: 0.14792472207959081
NN train accuracy: 0.7858473
NN val accuracy: 0.7965368032455444
a1=>
XGB Train accuracy: 76.54%
XGB Test accuracy: 77.92%
a2=>
XGB Train accuracy: 79.33%
XGB Test accuracy: 80.09%
tanh:
NN train loss: 0.16395572024905702
NN val loss: 0.14515615728768436
NN train accuracy: 0.7765363
NN val accuracy: 0.7922077775001526
a1=>
XGB Train accuracy: 77.84%
XGB Test accuracy: 80.95%
a2=>
XGB Train accuracy: 77.84%
XGB Test accuracy: 81.39%
Observations:
- For both activations relu and tanh, a2 as input performs better than a1
- Near or better accuracy for both train and test with a2 than X
- Neural Network with X vs. XGBoost with a1 & a2:
- relu:
- a1 is little better in train and worse in test
- a2 is better in train and same in test
- tanh:
- a1 is same in train and better in test
- a2 is better in train and much better in test
- relu:
Output:
- Run XGBmodel:
- with X as input
- using RELU:
- with a1 as input
- with a2 as input
- with a1 & a2 as input
- with X & a1 as input
- with X & a2 as input
- with X, a1 & a2 as input
- using TanH:
- with a1 as input
- with a2 as input
- with a1 & a2 as input
- with X & a1 as input
- with X & a2 as input
- with X, a1 & a2 as input
XGB Train accuracy: 76.54%
XGB Test accuracy: 80.09%
relu:
NN train loss: 0.15655751415360128
NN val loss: 0.14780039391863398
NN train accuracy: 0.7877095
NN val accuracy: 0.7965368032455444
a1=>
XGB Train accuracy: 79.33%
XGB Test accuracy: 78.79%
a2=>
XGB Train accuracy: 79.33%
XGB Test accuracy: 80.09%
a1 & a2=>
XGB Train accuracy: 79.33%
XGB Test accuracy: 80.09%
X & a1=>
XGB Train accuracy: 79.33%
XGB Test accuracy: 77.92%
X & a2=>
XGB Train accuracy: 79.33%
XGB Test accuracy: 80.09%
X & a1 & a2=>
XGB Train accuracy: 79.33%
XGB Test accuracy: 80.09%
tanh:
NN train loss: 0.16419628392939684
NN val loss: 0.14518083461048284
NN train accuracy: 0.7802607
NN val accuracy: 0.7922077775001526
a1=>
XGB Train accuracy: 77.84%
XGB Test accuracy: 80.95%
a2=>
XGB Train accuracy: 78.21%
XGB Test accuracy: 81.39%
a1 & a2=>
XGB Train accuracy: 78.77%
XGB Test accuracy: 79.22%
X & a1=>
XGB Train accuracy: 77.84%
XGB Test accuracy: 80.95%
X & a2=>
XGB Train accuracy: 78.21%
XGB Test accuracy: 79.22%
X & a1 & a2=>
XGB Train accuracy: 78.77%
XGB Test accuracy: 79.22%
Observation:
- adding X in the input doesn’t affect the final result that much.
- Need to do:
- New Dataset (bigger and with diverse uncorrelated features)
Abstract function to utilize both tanh and leakyrelu as activation- The increase in performance need to investegated further using a bigger Neural Network combined with big and diverse Data.
- Explore the Feature importance of these “Activation Features”
- Consider the memory usage of these activations, relu giving 6 features to use and tanh giving 32.